
Kaifeng Zheng
Things do not always work out. I'm working for a way out.
Summary of 445 Projects
Published May 10, 2024
Summary of 445 Projects
Project 0
Task1
首先,任务是实现Trie前缀树的Get、Put、Remove三种操作。和一般的树操作实现不同的是,这个Task要求Copy on Write。意思是说,在写操作时,获取Trie根结点的拷贝,然后在副本上面进行写操作,等写操作结束了以后再将它写回原本的Trie根。这么做的一个好处是读可以随时进行,因为写是在副本上的,在写完的那一个瞬间才会以类似”读“的形式写回去。
Task2
并发控制,主要是两点:
- 高级指针的使用,比如
std::unique_lock()搭配互斥锁 - 资源访问时的上锁逻辑
Task3
没什么好说的,就是调试然后看变量情况
Task4
很简单的两个函数实现,一个是根据Option将字符串Upper或Lower操作、还一个是注册该函数(在另一个cpp文件中调用刚刚实现的字符串函数)
总结
Task1是占用时间最长的,主要原因是
- 对现代C++语法不太熟悉
- 不熟悉COW的实现,还总是想着修改结点,而不是Clone()
- 熟悉了C++的现代高级语法,比如锁和高级指针的使用
Project 1
Task1
实现LRU-K算法,算是比较简单的题,第一次实现的时候,为了以实现目的为优先,于是直接给每一个函数都上了锁,等要Leaderboard挑战的时候再看怎么减小锁的粒度。
在本地实现都通过的情况下,Evict()一直过不了。后面发现,我的LRU-K在没有$k_{th}$引用记录的情况下,对overall最佳是采用LatestTimestamp,然而项目要求是Earliest。
Task2
缓冲池管理实现。理解每个函数的要求以后做起来其实是比较轻松的。同样的,为了减少思考,第一次实现直接给整个函数上锁。十分顺利地通过大部份测试,除了FetchPage, DelPage, IsDirty和Unpin。
错误原因:
FetchPage:从磁盘读取数据的函数用错了,用了strcpy。看了提供的测试代码,应该用memcpy。前者截断了'\0',而后者原封不动地拷贝内存IsDirty:因为在Unpin直接给page的dirty标志赋值为参数所给值,如果page本来是脏但是参数不脏就会导致错误。正确做法应该是求异或DelPage:一开始只是简单调用了ResetMemory,元数据没有重新初始化,导致错误
此外,Evict进行后,要从page_table删除对应键值对,但是顺序错了。在删除后,page_id已经被设置成INVALID的情况下试图删除,造成的结果就是frame看似还在池里。这是最主要的错误,是上述错误的部份原因。
Task3
页守卫的编写。最关键要理解它们的作用:
- Basic:负责自动Unpin
- Read:负责自动释放读锁和Unpin
- Write:负责自动释放写锁和Unpin
这一节的代码量实际并不高,但是却在这里卡了许久。最后是让代码看上去更“规范”一点的情况下过了测试。猜测是因为一开始调用Drop()和处理要丢弃的项,导致锁可能没有顺利释放,造成其它线程永久等待。
Leaderboard挑战
TODO,在通过Leaderboard测试的前提下,官方提供了一个Buffer Pool的Benchmark。根据官方建议和我自己的想法,可能的优化方法有:
- 前面提到的锁粒度减小,分别在LRU-K和buffer pool manager优化锁的使用
- Benchmark有8个序列扫描Scan线程,8个随机获取Get线程,一共16个线程。在LRU-K算法层添加请求类别这一参数,优化算法使其在Evict的时候能作出更有效率的决定
- 并行化I/O操作,其实就是1带来的好处
多线程编程,一定要注意函数内外是否会重复获取互斥锁,不然会死锁;还有就是操作的原子性,有的时候读操作用写锁是必须的,比如在Unpin之前的page检查。
完成情况:
-
锁粒度减小,一开始天真地以为把每个共享资源保护起来就可以了(用完就释放,导致前后不一致,见TIP)。最后的做法是把每个函数切割成两部分,第一部分是涉及到bpm的共享数据结构的部份,需要所有线程共用一把互斥锁保证访问顺序。第二部分是对页面
pages_的具体操作,使用了pool_size_个互斥锁,让每个页面得以并行运行。TIP:最后看上去过了,后面其实修改了很久,因为多线程出错很随机,最后才终于想明白。突破口是bpm_bench.cpp文件,考虑到这里只涉及到NewPage, FetchPage和UnpinPage,而NewPage只是用来创建。分析思路:首先Fetch读到的page肯定是不能被篡改的,因为篡改的唯一途径是evict,而pin值不为0是不可能的,就是说正在读的page是不可能被篡改的。那么就考虑数据写入的时候数据就是错误的了。造成写入错误的可能有:
- page_id_错误
- page_.data错误
此前的数据写入测试正常通过,所以判断是page_id_出错。我的代码是两段锁,但是这样保证不了前后读取page_id的一致性。于是我把锁的范围扩大,终于通过测试。从最后到达排位540,末尾水平。
-
尝试了LRU-K添加一个lru链表(最后总体长得有点像倒排索引),位次提升到440。但是对于区分Scan和Get的算法优化,我只尝试了把Scan添加到lru中(LRUReplacer),位次到435。就在写这段话的时候,意识到在BPM层面还可以对Scan只进行以下个性化的Fetch
- 检查是否在pool,在的话不计数
- 不在的话,也就是history为空,加一个远古时间戳——0
上述操作能尽量让本次Scan仿佛没来过,如果遇到了连续的Scan,返回的也会是最近的Scan。
经过完善Fetch优化,提升到了259。题目在Unpin的参数还预留了一个Accesstype,暂时先放下了。
总结
学到的东西:
- LRU-K的实现,全局时间戳
- BPM实现,锁的覆盖范围怎么确定、unique_lock等的使用
- Guard的基本原理,RAII技术、右值引用
- 互斥资源的保护
Project 2 Checkpoint#1
Task1
简单来说,就是完善B+树的page基类、internal page和leaf page的一些函数。前期刚开始做的时候被源码的意图弄得有点糊涂,这几个类其实也是在做后面的Task时逐步完善的。
Task2a
完成GetValue和Insert函数,现在能想到的要注意的点有:
-
GetValue: 只需要自上而下遍历树到相应的叶子结点就行了。写的时候被方向guide变量坑到了,一开始没有意识到二分查找的值和guide应该的对应关系。好在后面顺利修复了。关键词:二分查找、guide -
Insert:插入比较简单,只需要应对页的分裂的问题即可。但是做的时候状态不太好,索性照着教材的伪代码敲了,幸运的是没遇到什么bug,很快就通过了测试。中途SplitTest和ScaleTest没过(我想ScaleTest没过应该是Split的问题导致的)。到discord找线索,发现做B+树实现的人比哈希索引的人相对少好多。看到一个对于Split思路的hints,拷贝如下。总之按照这个思路过了一遍之后发现自己的Size调整有点问题,修改之后就过了。关键词:递归Make sure you follow this: “However, you should correctly perform split if insertion triggers current number of key/value pairs after insertion equals to max_size”.
Leaf page : on successful insert, max size = actual size? Split it. In other words, the size of a leaf page is the number of values.
Internal page : before insert, max size = current size (aka current number of pointers)? Split it. In other words, the size of an internal page is the number of pointers including the next page pointer.
SplitTest is a pretty invasive test that unfortunately tests the implementation details (because it is hard not to). So your code might be right but the autograder might not accept it. Though more commonly, people make some error with MoveHalfTo or similar functions.
-
补充:SplitTest后面因为更改了Split Leaf的写法(从先插入后split到先split后插,避免溢出),导致特殊情况(LeafMaxSize==2, InternalMaxSize==3的情况下没有处理好分裂操作,0位元素没有正确被剔除)下发生错误;另外,更改了刚刚说的先后顺序后,没有在最开始判断是否是已经存在的元素,导致元素会先被剔除后被判断,呈现的结果就是如下所示,
[1,2,3,4,5]基础上再试图插入[1,2],结果分裂为空:(3) (2) (4,5) () () (3) (4) (5)
总结
这次的Project难度还是挺大的,之前在课上了解的很多的优化方法,一到了实践,随着时间,我脑子里那些的优化理论都变成了最基本功能实现的编程细节。脚踏实地很重要啊!
补充:
并发测试因为页的的max_size比较大,因此测出了我的二分查找其实有点问题,会出错的情况是:已有key[1, 2, 3, 4, 6],想要插入5,此时应该返回4 错误代码:
int low = 0;
int high = page->GetSize();
while (low < high) {
int mid = low + (high - low) / 2;
if (comparator_.cmp_(page->KeyAt(mid), key) == 1) {
high = mid - 1; // 这一步会让返回的pos是第一个“不大于”目标的数
} else if (comparator_.cmp_(page->KeyAt(mid), key) == -1) {
low = mid + 1;
} else {
low = mid;
break;
}
}
修正后:
int low = 0;
int high = page->GetSize();
while (low < high) {
int mid = low + (high - low) / 2;
if (comparator_.cmp_(page->KeyAt(mid), key) == 1) {
high = mid; // 收敛更“收敛”一点,这样能确保返回的pos是应该插入的位置
} else if (comparator_.cmp_(page->KeyAt(mid), key) == -1) {
low = mid + 1;
} else {
low = mid;
break;
}
}
Project 2 Checkpoint#2
Task2b
树的删除操作,本次project最难。最开始是想着按照官网提示的Roadmap自己写出伪代码,但是脑子转不动。后面在油管找到一个印度女老师的B+树Delete操作讲解视频,简直太通俗了,瞬间理解,最后自己把Delete完成了。同时也是最耗费时间到Task!!绝大部分时间都是在Debug,出现错误的点为:
- 根节点特别判断没有做好,具体是:前一个if条件判断要求是根节点,后一个if(不是else if)又没有要求不是根节点,导致根节点被当作普通parent进行merge
==完整理解删除的两大操作:Merge和Borrow以后,这个操作从难以理解变为了比较难落实。==
Task3
Iterator实现,和前面的操作比起来过于简单。值得注意的点:
- End的判定,到底怎么样才算End?
- ++操作,怎么判断到没到底?到底了怎么办?
Task4
利用Project1的PageGuard非常好实现,只要注意写锁和读锁的使用和释放位置就行。
但是并发MixTest一直无法通过,涉及到的log都是说对应key不存在。
我自己测试了多达10000个key的插入,得到的树看似非常正常。再试了一下1000个key,发现key的顺序被打乱,!!!原来是我的BorrowFromInternal在向右sibling借的时候,我的实现只满足了max_internal_size为2的情况。
最后只剩并发Insert2和Mix1过不了,索性整个Insert函数上锁,居然过了。于是确定只是锁的问题。
Contention一直过不了。在并发Insert时偶尔发生Segementation fault (具体是在InsertLeaf和InsertParent),有时发生死锁。
死锁排查实况:
-
想到死锁可能发生的情况:buffer pool满了而且每个页都pinned,这时候如果请求HeaderPage而且池子里没有HeaderPage的话,就会锁住?不是。
-
找到Segmentation Fault,是由于latch crabbing的时候,条件判断错误了,只因我最开始将InternalPage的Size设计成key的数量,很混乱,总之错了+1+2的问题。现在还差ContentionBenchmark会发生死锁。
-
通过打印大量log,我发现,在两个线程的情况下,每次死锁前都是一个线程先输出FetchWrite后输出Fetch header page txn: xx。问题是这时候没人拥有锁啊!为什么会死锁呢?
-
原来死锁来自同一线程重复请求header page,第二次请求来自
next_page_id(从根到叶的途中),理论上这不可能发生。发现是因为buffer pool manager没有将此前NewPageGuard得到的page flush到磁盘(通过打印log验证确实没有),导致可能获取一个空页,进而导致死锁。 -
ok,我知道了,是因为BPM的并发控制没有做好。我试着上一把大锁给BPM,所有问题都消失了。
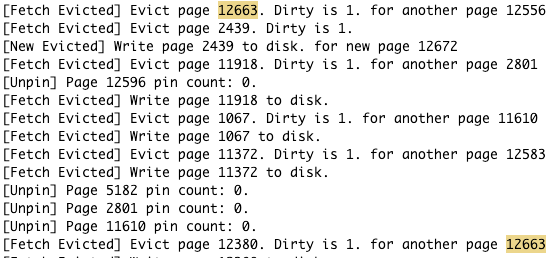
上图:page12663没有Write page to disk就再次被请求
问题来了,BPM出现了什么问题?见下文。
总结
这次实验真的花费了我大量的时间和精力,而其中大部份都花费在debug上。而出现的问题大多又是一些特殊情况的判断和边界细节处理上。总之就是,以后出现问题,优先考虑程序在特殊情况下的表现。最难的操作:
- Borrow 哪个key被借走,借到哪里,哪些key要删除
- Merge 搞清楚哪些key被删除,哪个key被上传
- Split 主要是leaf可能会溢出,需要特殊照顾
(4,7)
(2,3) (5,6) (8,9,10,11)
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11,12)
> d4
> p
(8,7)
(2,3) (4,8) (9,10,11)
(1) (2) (3) (5) (6) (7) (8) (9) (10) (11,12)
Leaderboard 挑战
虽然做完了,但是排名特别低,我不是很服气,写个乐观锁吧。
然而写完以后,事情没有这么简单。遇到了和之前类似的问题,脏page不写回!但是后来修改了一些代码,复现不了了,甚至加了Flush也不管用。
- BPM大锁+B+无手动FLUSH,可过Contention : 4.39和1.46
- BPM原样+B+手动FlushNewPage,可过Contention:5.35和1.1
- BPM大锁+乐观锁,不可过Contention:0.62和
最大疑点:BPM在Evict的时候为什么不Write脏页??
最后终于知道了,是因为虽然每个页都上锁了,但是这只能保证页在写入时之间是互不干扰的,读没有保证。例如:
线程A:evict其他某个页,然后读取page 1
线程B:出于evict,要刷page 1脏,已经标记page#1不在buffer中
现在,线程B正在执行,但是还没有开始刷脏,同时A开始读取page 1。虽然他们都获取了锁,但是锁是各自的target(buffer_pool对应槽位,而不是page_id),线程A如果比B先完成Evict操作,那么A就会尝试从磁盘读page1,但是此时磁盘的page1不是最新的,因为线程B还没有刷脏完成。这就导致前面的疑点发生,事实上,并非是Evict了但是没有write,而是还没write就Read了。还没来得及打印write结束,程序就终止或死锁了。
对于这个问题,做完所有Projects后,我现在有两个可以解决的想法:
- 在脏页成功刷盘之前不要把
table_map_的锁释放,这样其它线程就会在刷盘完成了以后才会去试图从磁盘FetchPage - 参考P4的做法,为写evict这个操作配置一个请求队列,每个page_id都有一个队列,读者来了可以读尾部(最新)的page,每个page写入过程可以另起线程,并行I/O
至于为什么乐观锁出错,出错场景展示在下面。推测插入顺序是7、6、8
猜想:8申请了[6, 7]页的写锁,而这个写锁目前正在被一个线程插入9。页发生分裂,变成[6], [7, 9],这时8才获得[6]的写锁,但是这个页已经不是8应该插入的了。

刚刚尝试了一下在获取写锁之前先提前判断一下大小,相当于双重判断size是否符合,结果居然就可以了!然后试了一下把获取写锁以后的大小判断去掉,也可以!原来是我的条件判断位置错了!
再次强调了那句话:线程只有拿到锁以后数据才是安全的。
还原一下两种判断位置的区别: 如果是获取写锁才判断,很显然会发生上面提到的错误。然而,如果读锁期间判断,由于本线程还握着读锁,可能有其他线程正在等待写锁,那么这时我提前判断,就避免了因为没有马上拿到写锁而导致页不一样的问题。因为如果页会分裂,我在读锁就保证了信息全面。但是如果有两个或者以上写锁在等待呢?
这样就过了,但是分数反而低了。?
Project 3
Task#1
实现以下Executor:
-
SeqScan
要注意判断是否被标记为已删除
-
Insert
注意插入index的key是怎么获取的(通过key_schema锁定当前index涉及的列)
-
Update
同样,要注意处理index,先删除后插入
-
Delete
Update的子集
-
IndexScan
通过获取此前完成的IndexIterator来获取,值得注意的是发现并完善了此前边界情况
End()一些不太好的处理,比如初始化是INVALID_PAGE_ID会导致报错等等
坑点:
- insert, update, delete操作都是一次完成,输出的tuple是发生变动的row数
- 注意首次Next必须返回True尽管可能得到的tuple是大小为0
- 注意index需要根据它的key_schema进行插入key,不能直接将整个tuple插入index
Task#2
最痛苦的就是看懂源码和debugging,但是一旦理解了源码原理,上手就很快
完成聚合和加入:
-
Aggregation
在Init的阶段把所有来自child的数据flow截断并使用hash计算和存储要求的结果,在Next迭代返回
头文件的实现学到了把相同hash值根据不同情况(如count每次+1、sum每次+input[i]、minmax记录最大最小)合并计算的方法
-
NestedLoopJoin
使用两层循环迭代来自child的tuple,值得注意的是为了保存进度,使用左右成员变量记录当前位置。如果能一次读完所有tuple一次性返回会简单很多
-
HashJoin
参考Aggregation实现了JoinKey和JoinValue,不友好的一点是不能直接用来调试,因为还没完成优化器实现
优化器实现后发现漏了哈希冲突处理,完善策略使用了简单的线性探测
-
NLJasHashJoin
实现将NestedJoin转换成HashJoin的优化器,凡事
=条件的Join都能转换成HashJoin这里只要求实现至多一个
and的情况,如果要实现多个and都能处理应该写一个子程序对expression二叉树进行处理,把所有左和右(表)叶子结点(ColumnValueExpression)的列都拼接到一起,然后基于此构建一个新的HashPlanNode继承原有NestJoinPlanNode的children,特别注意ColumnExpression是左表还是右表,PlanNode倒是默认都是分好的
Task#3
实现以下功能:
-
Sort
由于是内存内的sort,直接截胡(阻塞操作)所有tuple,然后对它们进行排序即可
排序需要实现一个自定义的排序函数,结合order_by所给的线索进行排序
-
Limit
甚至更加简单,只需要维护一个计数器,在计数器达到限定的tuple数就可以返回false了
-
Top-N优化
简单来说,就是如果出现了
order by xxx limit n的语句,不要把所有tuple保存完再统一排序,而是一边读取一边排序,同时丢弃超过容量的tuple因为上面实现了HashJoin,这里的优化规则实现起来就比较熟悉了
总体来说,做了Task#2再来做这里会觉得轻松很多,也有可能是因为对代码理解更深了,知道每个部份是在做什么。
Leaderboard
Q1
利用Index的有序性,对where操作进行优化,包括where的列是index主键子集的情况。
初步分析,对于where是index列的子集的情况,可以按以下步骤:
- 根据FilterPlan找出条件
condition - 遍历Index,找出包含
condition所有列的index,key列少的优先(利用率大) - 因为index是递增的,只需要找到左侧起点(要么从头,要么从某个点)开始遍历B+树,==在遇到第一个不符合
predicate的表明结束,返回false即可。==
目测难点在于找到左侧起点
完成后总结:
上面的分析基本正确,需要注意:
- “第一个不符合predicate就表明结束”这一结论,不适用于
x>=90 and y=10中y的情况,很显然这种情况下应该返回的分布不是连续的,所以没办法提前锁定结束位置,但是以下这三种情况:x>, x>=, <x, <=x可以帮助我们锁定起点,跳转到最早的可用点。
Q2
谓词下推,就是把在join后的Filter移动到join前,减少Join的工作量
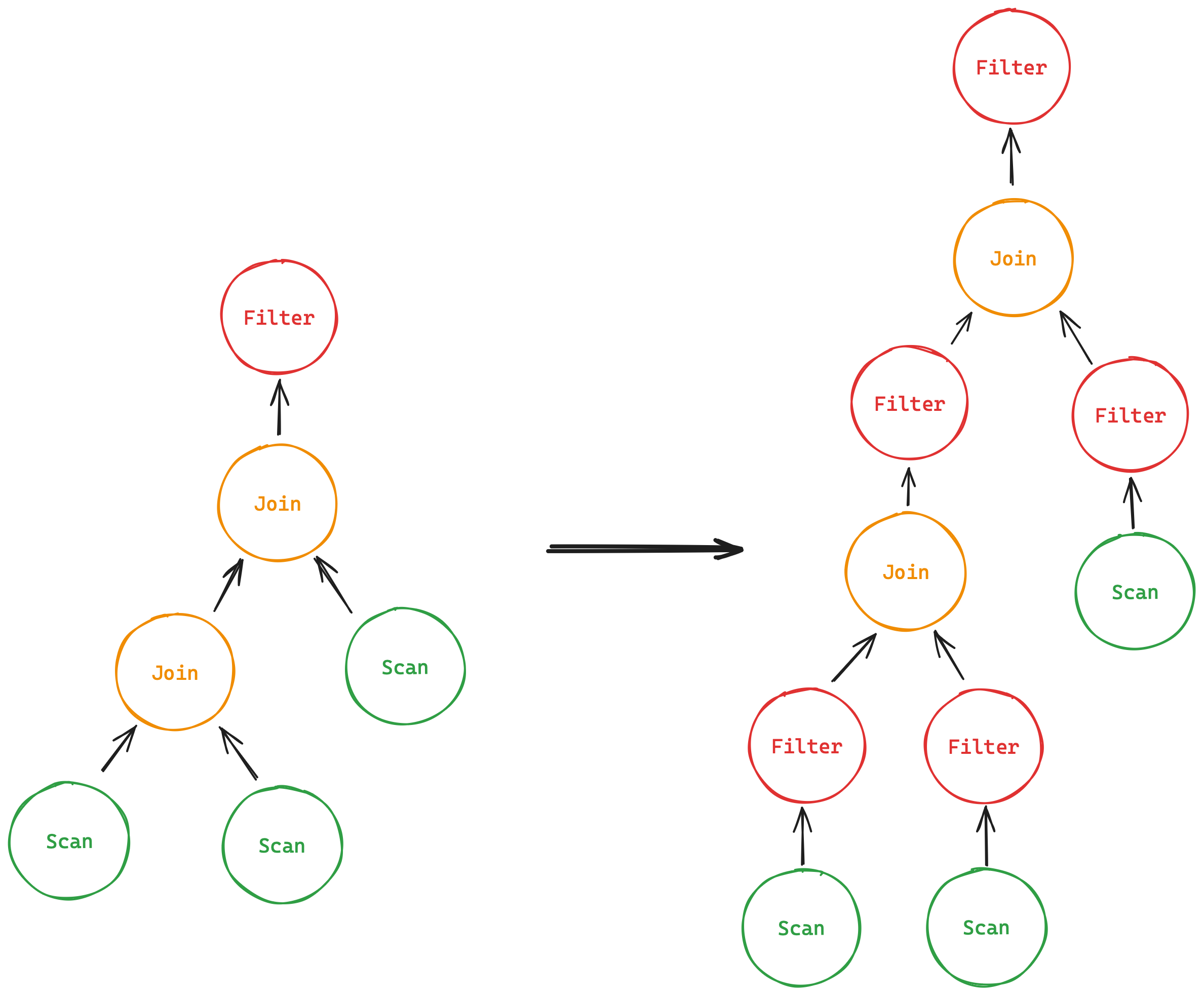
初步分析:
- 找到Filter跟随Join的情况
- 分解Filter的predicate,把它的col分配给Join的左右子结点
- 如果子结点是Scan,直接把predicate赋值给它
- 如果子结点是Join,那么赋值给它之后,再次对它调用本函数
- 两个子结点执行完后,就应该会得到右图。注意Filter并非实际存在,而是以
predicate的形式存在PlanNode中
完成后总结:
首先,弄清楚自己在做什么真的很重要。根据图来理解,事半功倍,一些实现时的细节:
- Join一定会在Join的左子结点,知道这一点可以简化实现时的一些操作
- 正确地判断Filter中的列是属于Join左边的那个Filter还是右边的(通过获取左表的列数判断)
- 将Join上方的Filter“肢解”给子结点后,分别继续对子结点递归调用本函数,因为子结点也有可能是Join
- Expression树有可能会有Logic, Comparison, ColumnValue和Constant,应对策略分别如下:
- Logic,子结点可能是Comparison或Constant,直接将它们分别传入本函数
- Comparison,子结点可能是ColumnValue或Constant,对于前者,根据它的
ColIdx决定是要把当前Comparison放到“左边”还是“右边”。Comparison本身应该被视为叶子结点 - 有时Logic的子结点会是Constant结点,什么都不用做,不要放到“左边”或者“右边”
- 最终得到的新的predicate会是3个,分别是要给左Filter、右Filter和自己的Filter的,值得注意的是predicate有可能是空的,那么需要配置一个true Filter
- Merge Filter操作放到这个优化规则后(
MergeFilterScan,MergeFilterNLJ)
Q3
疯狂的数据科学家,一堆奇怪的SQL里穿插了一个永远都为false的条件,这会导致SeqScan无意义地循环,必须提前制止这种行为。此外,这个数据科学家还创建了很多无用的聚集函数,得想办法把这些聚集函数也给优化掉。
实现后总结:
要实现的有:
IsPredicateFalse检查函数OptimizeDropFalseScan替换永为false的那层executer为dummy scan(空的ValuesPlan)FindUsefulColumnsforAgg传入Expression,根据这个Expression树寻找实际需要的col_idDropUselessAgg通过检查双层Projection,确认没有必要的聚合函数计算,只保留有需要的部份
重点总结一下IsPredicateFalse:
- 考虑三种结点:Logic、Comparison和ConstantValue
- Logic只能是And或Or,只需要递归判断它子结点是否为永False并统计,结合And和Or就能知道是否为永否
- Comparison的子结点有ColumnValue和ConstantValue两种,对应的情况有1==2, 1!=1和v1!=v1这三种永否
- ConstantValue被认为直接反应这个Filter的predicate就是永真或永否,直接返回相反值(比如
ConstantValue==false,说明永否,返回true)即可
再说说DropUselessAgg:
- 规则考虑的是双层Projection,最后一层是前面一层的子集
- 首先压缩两层projection为一层:把不需要的从子层去掉,把需要的提取出来替换到上层,只保留上层
- 对于此时的Projection层,
expressions_即子集,寻找有效col_id,也就是在Aggregation层要保留的 - 步骤简述:
- 中间结点为ArithmeticExpression,叶子结点为ColumnValueExpression(当然也可能是ConstantValue,但是没有用处)
- 中间结点则递归子结点
- 遇到ColumnValue,记录这个column的
col_id
- 得到有用的
col_id以后,就可以通过agg_plan的schema中的column_找到有用的列,通过这些列的名称又可以找到聚合函数(agg开头e.g.agg#1) - 最终利用上面的信息,就可以构建一个简化的plan了
不足之处:
- 只考虑了两层Projection的情况
- 得到最后的
col_id等信息后,没有将它们向前“靠拢”,虽然这似乎不会导致运行错误,因为虽然数值不是连续的,但是它们都是对应的 group_by_没有去掉无用的key
结果表现:
优化完成后,Q1表现最佳,排名到了13;Q2和Q3分别排33和36位。如果前面BPM的并行化I/O有实现的话应该还能再高一点。
Project 4
Task#1
实现LockManager,具体包括对Table和Row的Lock和Unlock。
最开始按照笔记自己写了一遍,但是代码丑陋且混乱,评测不通过。于是按照官方的函数框架重写了一遍,比较顺利地通过了测试。
最初的实现想法:
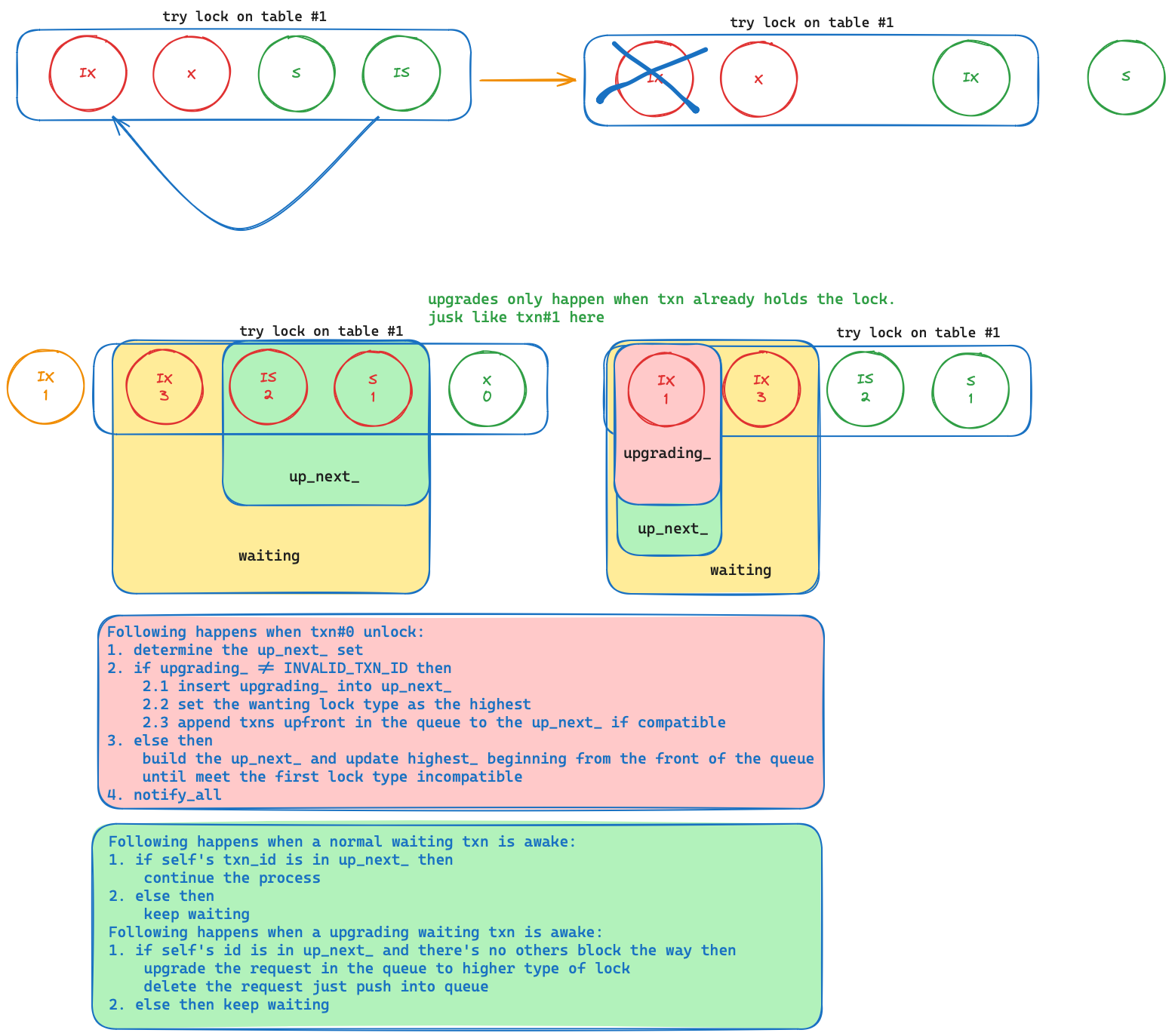
要注意的点:
- 按照笔记提示完成函数
- Lock顺序简单描述如下:
- 事务是否能请求锁(根据隔离级别
- 请求row锁要额外检查是否已经在表上添加了对应的锁
- 检查自己是否已经持有锁,如果是低级的锁,标记升级;如果是持有更高级的锁,或者是不匹配的升级,中止事务
- 现在是否有事务在等待,是则wait;否则跳过沉睡
- 唤醒后检查是否可以获取锁,具体为先查看自己是否为下一批目标事务,然后检查当前队列已获得锁的请求与自己是否兼容
- 若都满足,走出wait循环;否则继续wait。每次唤醒后还要在循环体内检查是否已经被abort了,是的话要将自己的请求从队列中删除并广播一次唤醒其他可能在等待中且符合条件的事务,最后返回false
- 赋予事务锁,更新事务的book,修改granted为true,完成
- Unlock顺序简单描述如下:
- 检查是否真的有锁
- 根据隔离级别修改事务状态
- table锁要额外检查是否还有row锁没释放
- 更新事务book
- 从队列中删除当前事务的请求
- 唤起下一波事务
- 多线程编程还是那句话,只有拿到了锁之后的数据才是可信的!
可以改进的点:
- 因为事务每次被唤醒会调用IsAllowedToGrant函数,这个函数的做法是遍历当前队列,检查兼容性(隔离)和优先性(FIFO)是否同时满足。对于其中的兼容性,可以通过维护一个highest变量记录当前锁的最高等级,所有不与它兼容的锁在它释放(然后更新highest)前都不能被授予。这也是我最开始的实现。但是实现可能出错了,为了确保正确性还是先用循环实现了。
Task#2
死锁检测实现,还算比较好实现。简单来说就是有一个背景线程持续地根据当前的队列情况建立一个Graph,使用DFS检测环的存在,剔除最年轻的事务。
顺序简述:
- 首先,通过当前所有的请求队列记录等待的边,形成Graph
- waitings –> holdings,而且是互不兼容的锁才会形成等待边
- 获得的waits_for_ map存放了所有边,将所有事务id排序存放,从lowest开始DFS(为了test的正确性),map的second(vector)中的元素也是顺序存放的
- 找到环了以后,找出最大id的事务,然后将这个事务的请求从所有队列中删除并标记为aborted,再次找环,直到没有环了为止。
- 清除所有环后,在所有队列上尝试授予下一波事务
这里卡了一段时间,倒不是因为很难,而是它有一个GetEdgeList函数要返回所有边,来检测我的正确性。我是用txn_mgr来获取所有事务id的,而test只是给waits_for_专门赋值了而已,并没有真正事务存在。
Task#3
逻辑并发控制!简单来说,就是Task#1完成了锁的功能,现在要来用这些锁了。要求的其实很简单,只需要满足SeqScan、Insert和Delete这三个executor就可以。
- SeqScan:最主要的。有一个IsDelete()的Context上下文函数,提示是否需要持排他的锁。
- 对于Table(
Init函数),拿到oid后,先检查是否必要加锁,因为可能已经有了更高级的锁。 - 对于Row(
Next函数),拿到rid后,同样先检查是否必要加锁。此外,因为实现了predicate push down,如果这个row不符合条件或者是已经被删除的,要再将它Force Unlock掉,因为事务不需要这个row。 - 最后,根据隔离级别选择性的释放S锁
- 对于Table(
- Insert:
- 在
Init函数对表上IX锁(?) - 在
Next函数记录加入的row到write_set,以便后续对abort事务进行回滚
- 在
- Delete:
- 如果在SeqScan是通过IsDelete()判断并提前上了排他锁,这里在
Init函数就不需要上锁了 - 同样在
Next函数记录删除的row,以便回滚
- 如果在SeqScan是通过IsDelete()判断并提前上了排他锁,这里在
- 一定是要拿到锁,再Fetch资源!
然后就是两个事务终结函数:Commit和Abort
- Commit:没什么要做的,只需要把事务所有持有的锁释放即可(根据book)
- Abort:根据之前记录wrtie_set_,对其元素倒序执行,就可以实现回滚。
Leatherboard
Hint1
Predicate pushdown to SeqScan,这个在P3就实现了,提交后比最低有3到5的提升。好处是减少SeqScan上传的元组数,进而减少上锁的row数。
Hint2
Implement In-Place UpdateExecutor,因为之前UPDATE操作是用DELETE+INSERT实现的,如果update一步到位,想必会快很多吧!但是这个要改的话涉及到B+树的原地操作,直接贯穿了3个Project!而且我第一时间也没把握能顺利完成。遂遗憾放弃。
Hint3
Use Index,好巧,这个我在P3也实现了。但是这里有一点不同:因为key不会重复,所以如果predicate是CompareType::Equal的话(e.g. 只有一个=),就可以获取一个tuple(若有)后确信后面再没有匹配的row,可以提前退出。但是可惜的是,运行bench的时候出现了死锁。而且是latch死锁而不是lock死锁。
现象有二:
- DeleteExecutor在执行DeleteEntry的时候Fetch B+树的根结点页发生死锁,理论上不应该发生的,怀疑是线程两次获取了这个页面。
- 注释掉DelteExecutor关于更新Index的操作后,程序在调试时不会发生死锁(快速点击其实还是会),在直接运行下会发生死锁,怀疑在别处还有死锁。
原因推测:
- 线程在运行到索引的Remove函数必定发生死锁,很大概率是这个线程获取两次根结点的问题。
- 一开始以为是在IndexScan,树的Iter在最底部从左往右走;而在Delete和Insert,锁从上到下,获取锁的方向不一致(写到一半,发现这个不是原因。因为基于Hint3本身的实现,iter不会向右移动,但仍然会出现死锁)说明程序在别的地方还有其它重复两次获取同样的锁
总结
至此,所有Project都已经完成。现在是,感谢时间!首先要感谢Andy,把这个课程公开,让我有机会接触到在我本校所不能得到的知识;感谢TA们,感谢他们打造了这样一个bustub,还在discord上解答非CMU学生的问题;最后感谢自己,感谢我坚持到了最后。
一些可改进的点集合:
- BPM并行I/O实现
- B+树结点可在满size前借给邻居,减少连续地分裂
- 执行计划还可以有更多优化
- Update操作原地进行